.png)

Unleashing the biomanufacturing revolution with an enzyme acceleration revolution




Enzyme is the core hardware of biomanufacturing
The green transition of the world economy needs efficient biosolutions.
In labs around the world, there are now numerous proof-of-concept bioconversion pathways, going from 0 to 1, offering endless promises for a sustainable economy: food/feed ingredients, plastic monomers, and long-duration energy storage molecules.
Looking at the market, there are still too few biomanufacturing processes being economically competitive against fossil fuel-based ways, the “1 to 100”, compared with its vast potential.

A biomanufacturing revolution needs an enzyme acceleration revolution.
Enzymes are the reason biomanufacturing can happen. In essense, biomanufacturing pathways are enzymatic conversion pathways linking the feedstock to the end products.
It’s impossible to have a fast bioprocess when the enzymes are slow. It’s hard to have a slow bioprocess when the enzymes are fast.

The ENZIDIA® Evolutionary SuperWheel
Enzyme optimization is fundamentally constrained by two bottlenecks: 1) evolution speed (namely screening throughput, - "the numbers game"), and 2) intelligence (limited by data, - "the information game").
1. Evolution speed - the numbers game
2. Intelligence - the information game
.png)
The ENZIDIA Evolutionary Wheel - an "AI-second" reinforcement learning loop:
1. Build and screen a massive library
~1010 variants screened per run. This is 10,000,000 x greater than robotics-based platforms, and 10,000x greater than microfluidics-based ones.
2. Collect massive data
~106 labeled enzyme sequence-performance data per run. This is 10,000 x greater than mainstream platforms (cost held equal).
3. Learn from the massive data through AI.
4. Design the next large & intelligent library, informed by real big data.
Loop to step 1.
With evolution speeds 10 millionx faster and AI-directed data collection 10 thousandx greater than mainstream platforms (and even more than nature), we can accelerate nature’s most powerful manufacturing machines like never before. The scale of revolution this can unleash is hard to predict, but it won’t be small.
The ENZIDIA platform has been breaking enzyme bottlenecks on a roll
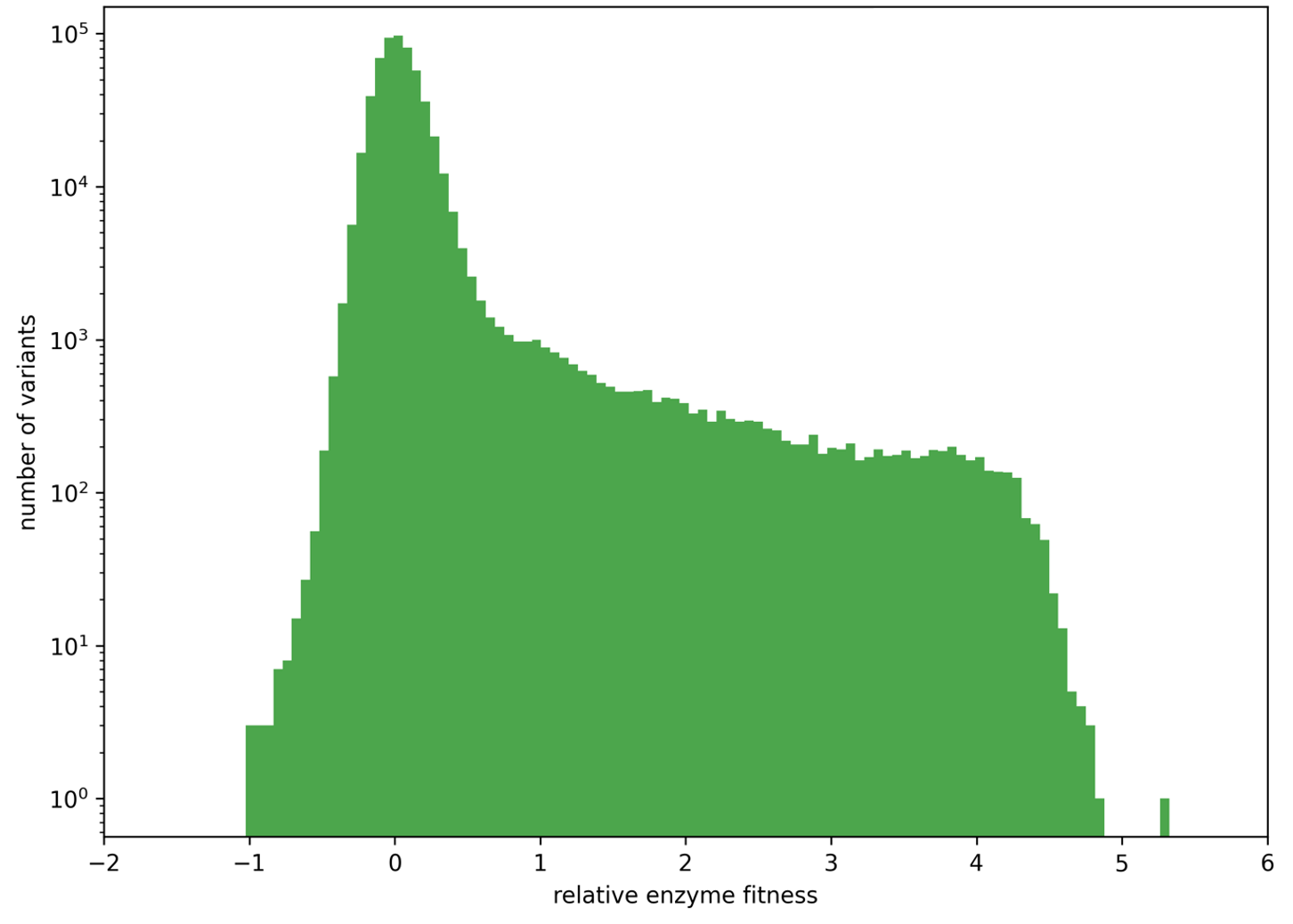
A dataset with >100,000 data points (validated data)
.png)
The power of unprecedented data + cutting-edge AI
(preliminary data from Feb. 2026 with Frances Arnold lab & ExoZymes)
When combined with cutting-edge AI, the massive dataset enabled the design of a variant with over 16 fold the performance of the original sequence, several folds greater than the best variant from a massive screening run.
Patent-pending. Read the paper here.
(The benchmark sequence is commonly used in patents and papers. Enzyme performance is defined as level of product produced in a given timeframe, incorporating multiple contributing factors.)
Patent-pending. Read the paper here.
Should our next project be the super-charged engineering of the bottleneck enzyme in your bioprocess?

A new paradigm of enzyme engineering


Microfluidics-based platforms
The Enzidia Team














Partner with Enzidia for the most efficient enzymes and cell factories
Long-term exclusive partnership for continuous optimization of enzymes and strains for a given chemical, ensuring industry-leading position in bioprocess efficiency and cost competitiveness.




In addition: no restriction on the partner to disclose the success or failure of partnership projects. This is not a common practice. While we may not remain successful in 100% of the cases we work on (so far we are), we believe that having such transparency is essential to establish ENZIDIA as the best and most trusted choice in the industry.
If you are developing great AI tools for protein optimization, you still need the data, especially labeled data, to train the AI models. Using our proprietary technology MillionFull (https://www.biorxiv.org/content/10.1101/2025.10.24.684421v1), we can collect millions of sequence-fitness datapoints for your target enzyme and protein. Properties we can collect data for include enzyme catalytic efficiency, protein expressibility and foldability in bacterial hosts.
Our uniqueness doesn't come from business models. No need to fit into the models above. - We fit them to your needs.
If you are looking to make your bioprocess the most competitive on the market, get in touch today.

FAQ

Most enzymes used in industrial biotech can fit the ENZIDIA platform. The current version of the platform is especially suited for enzymes involved in cell factories.
We will let you know whether a problem can fit our platform, and if so, the difficulty level on a scale of 1-10. Just book a call or write a message with the buttons right below this section.
We are here for you


Enzidia’s Core Principles: Truth, Mission, Learning
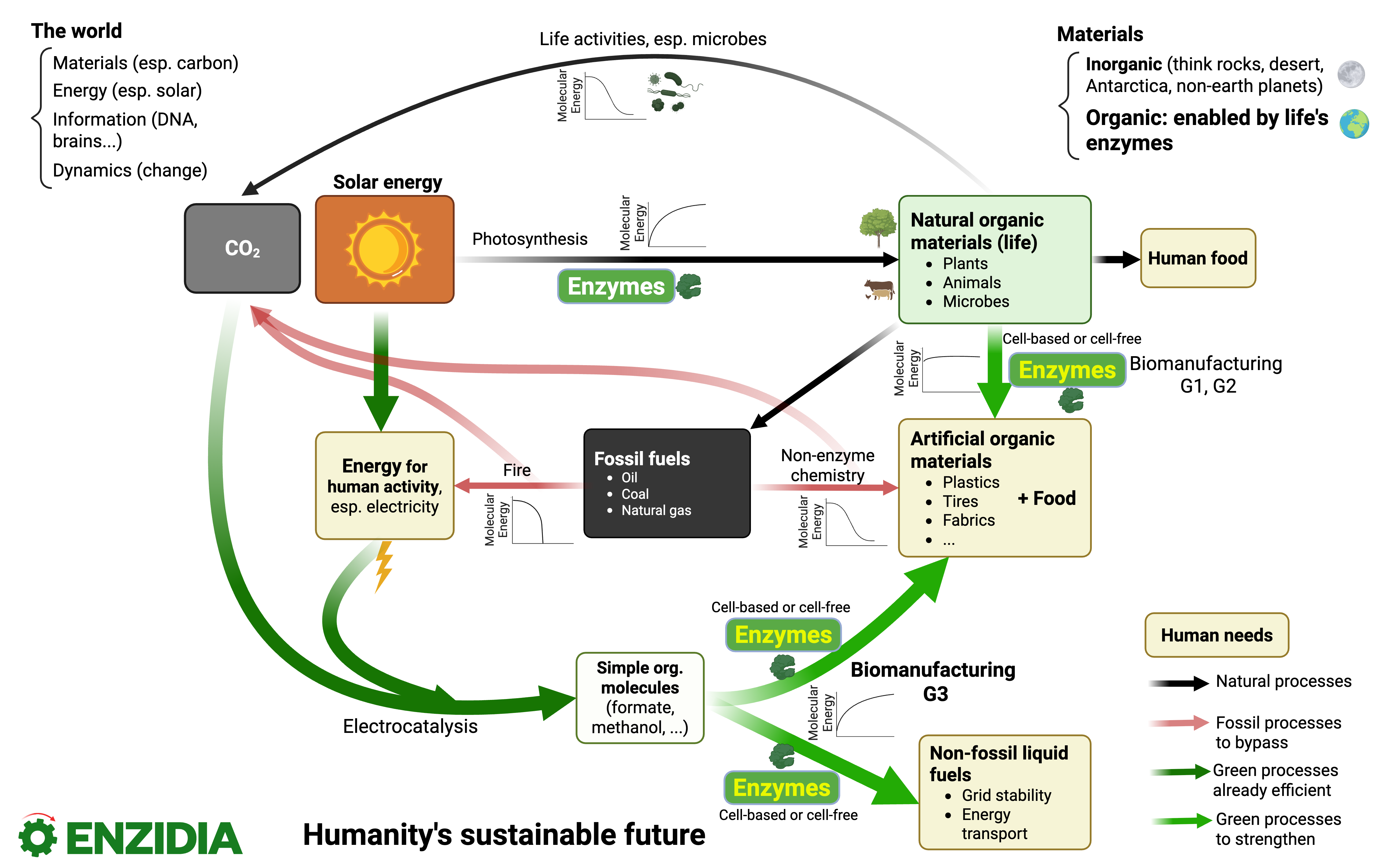
Our vision of humanity's sustainable future
Enzymes are the world’s most powerful manufacturing machines.
Imagine Earth without enzymes. It will be of barren lands and sterile sea, rocks and deserts. Enzymes made the entire organic living world possible. Even fossil fuels, the predominant feedstock of today’s economy, came eventually from enzymes’ work. Enzymes are not the predominant human manufacturing approach yet only because we hadn’t had the best way to tame them.
It is time to move humanity past that age.
Our journey is catalyzed by:








